The Science of AI Citation
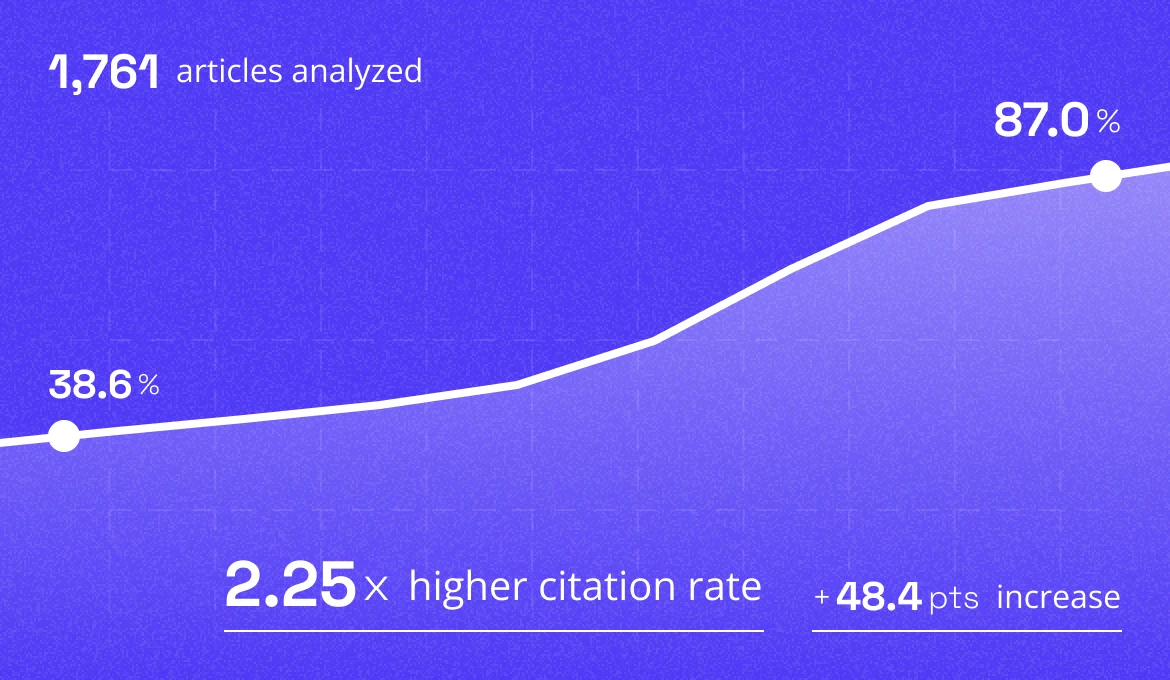
The Athena Citation Engine scores how likely AI systems are to cite a piece of content. We validated it on 1,761 published articles: top-decile content was cited 87% of the time, bottom-decile 38.6%.
AthenaHQ
Labs Team
What we found
AI answers now sit where search results used to. Ask ChatGPT or Perplexity a question and the model writes an answer, then cites a handful of sources. Those citations are the new visibility.
Brands used to compete for rankings. Now they compete to be the source the model quotes. That raises a concrete question:
Which content does AI actually cite?
We built the Athena Citation Engine (ACE) to answer it. ACE scores a piece of content by how likely AI systems are to cite it, and we use that score to generate and revise content before it ships.
To check whether the score means anything, we scored 1,761 articles that had been live at least 90 days, long enough for AI systems to find and cite them, and compared the scores against what actually got cited. Sorted into ten equal buckets by score (deciles):
- Bottom decile: cited 38.6% of the time.
- Top decile: cited 87.0% of the time.
- Top-decile content was 2.25× more likely to be cited than bottom-decile content.
- Score and citation rate correlated at 0.90 (R² = 0.81).
Citation is not random. You can measure it, model it, and write toward it. ACE is the first model we built to do that.
The problem: predicting citations
Most AI content tools generate. They help you write articles, summaries, and product pages. Generation answers whether you can produce something. It does not answer the question that matters in AI search:
Will this content get cited?
Two articles can be equally accurate and equally well written, and one gets cited constantly while the other never shows up. That tells us citation follows patterns. We treat finding them as a prediction problem: given a piece of content and its metadata, estimate the probability that an AI system cites it.
Formally, we estimate P(citation | content). That turns AI search optimization from a matter of taste into something you can measure.
The Athena Citation Engine
ACE has two parts: a model that predicts citations, and a workflow that uses the prediction to write and refine content.
- Citation prediction
- Citation optimization
Predicting citations
ACE reads a piece of content and returns a score between 0 and 1. Higher means more likely to be cited. It is trained on real citation outcomes, not on what reads well, because:
Good content and cited content are not the same thing.
Writing can be clean and still get ignored when it lacks clear sources, specifics, or the phrasing models pull from. Content that is specific, sourced, and matched to what people actually ask tends to get cited. ACE models that gap directly.
Building context
Before ACE writes or revises anything, it assembles what it knows about the brand:
- Brand documentation
- Product information
- Knowledge-base content
- Approved claims
- Approved source URLs
- Internal links and external references
- Editorial and brand-voice guidelines
The goal is not only content that gets cited. It is content that gets cited, holds up factually, sounds like the brand, and can be checked.
The optimization loop
ACE runs inside a loop:
- Build context from brand assets
- Draft several candidates
- Score each candidate with ACE
- Keep the strongest one
- Generate variations
- Re-score the variations
- Check claims and brand fit
- Publish
Instead of trusting one draft, we generate several and judge them against a score trained on what actually gets cited.
Why a general model is not enough
ChatGPT, Claude, and Gemini are strong writers. They are not citation predictors. Out of the box they do not know:
- Which prompts matter most in a category
- Which sources get cited over and over
- Which competitors get referenced
- Which content patterns line up with citations
- Whether a given article will get cited
They have also never trained on a record of what got cited and what did not. General models write content. ACE scores it against citation outcomes. We are not trying to replace these models. We use them, and ACE is the layer that tells you how they see, cite, and recommend your content.
How we tested it
We ran ACE against content that was already published and already had a citation history.
The dataset
- 1,761 published articles
- Live at least 90 days
- An ACE score for every article
- A known citation outcome for every article
We used a 90-day floor so AI systems had time to find and cite the content.
Every article had both ACE score & verified citation outcome
What counts as cited
An article counts as cited if it showed up in at least one AI answer during the window. The outcome is binary: cited or not.
The procedure
- Score every article with ACE
- Sort the articles by score
- Split them into ten equal groups (deciles)
- Measure the citation rate in each group
If the score works, citation rates should climb as the score climbs.
Results
Higher ACE scores correspond to higher AI citation rates
Across 10 score deciles, the observed share of articles earning at least one AI citation climbs from 38.6% to 87.0%.
Validation set: 1,761 published articles live ≥90 days. Outcome = article received at least one AI citation. Correlation measured at the decile level.
The headline
Top-decile content got cited 87.0% of the time. Bottom-decile content got cited 38.6% of the time. That makes top-decile content 2.25× more likely to be cited.
Score and citation rate correlated at:
0.90 (R² = 0.81)
The score tracks real citation behavior.
Reading the results
The point is not just that high scores beat low scores. It is that the citation rate went up at every single decile. That steady climb means the score works for ranking and triage: higher score, higher citation rate; lower score, lower rate. So you can use it to decide:
- What to publish
- What to rewrite
- Which topics to fund
- Which drafts to expand
The score gets most useful above about 0.73, where citation rates jump. Past that point ACE flags the content most likely to get cited before you publish it.
What makes this defensible
The edge is not generation. Plenty of tools generate. The edge is the combination:
- Citation outcome data
- A model trained on that data
- An optimization loop that uses the score while writing
- A feedback loop that improves both
The data
We watch what AI systems cite. Every observation is a labeled example of cited or not, and that dataset is the foundation of ACE.
The model
ACE trains on citation outcomes, not on quality scores. It learns what actually correlates with getting cited.
The loop
The score lives inside the writing process. It is not a dashboard metric. It is the objective we optimize while drafting and revising.
The feedback
Every run teaches us more about prompts, citation patterns, source preferences, and outcomes. More content means more observations, better models, and better calls on what to write next.
Limits and what is next
This shows the score predicts citations. It does not prove the score causes them; that is a correlation, not a controlled experiment.
What ACE can estimate
- Likelihood of citation
- Relative source strength
- Signal contribution
- Model-level citation behavior
What ACE cannot guarantee
- Exact future citations
- Individual model decisions
- Real-time source volatility
- Platform-specific changes
Next:
- Controlled experiments that change content and watch the effect
- Per-engine citation prediction
- Prompt-level citation analysis
- Predicting how often content gets cited, not just whether
- Tying AI visibility to revenue
We also want to see how citation differs across engines:
- ChatGPT
- Perplexity
- Google AI Overviews
- Gemini
- Claude
- Copilot
They likely have different preferences, and we can model each one on its own.
Where this goes
ACE is our first model. The bigger goal is AI search intelligence. As AI becomes the main way people find information, companies will need to answer four questions:
- How do AI systems describe us right now?
- What moves citation and visibility?
- What should we make or fix?
- What does it do for the business?
We are building the layer that answers them. ACE is step one.
If you publish content today, it already has a citation score, whether you measure it or not. ACE is how we stopped guessing what it is.
Become the Brand AI Trusts
See, Act, and Win on AI Search and Beyond
Keep Reading
What Is AI Share of Voice?
What is share of voice in AI search? Learn how this new metric measures brand presence in AI answers and discover how to calculate, track, and improve it.

Platform-Specific Enterprise GEO Strategy: Optimizing for ChatGPT vs. Gemini vs. Claude vs Perplexity
The Ultimate GEO & AEO Platform Buying Guide for Enterprise Teams
How to choose the right tool to win on AI search in 2026
See AthenaHQ in Action
 Rootly
Rootly10x Increase in Citation Rate
GEO became Rootly's #1 growth pillar. With ~10x citation rate growth and +126% mention rate on non-branded prompts, Rootly transformed AI Search into an executive-level operating channel.
 Lago
Lago50% Increase in Demos from AI Search
Lago achieved a 50% increase in demos from AI Search after implementing Athena. With 11x growth in AI Overview impressions and exploding citations, Athena became their command center for GEO.
 Nuvadermis
Nuvadermis3x Share of Voice in 3 Months
Nuvadermis grew Share of Voice 3x in 3 months, with on-page citation rate climbing to 20%+ against a 4% category average, taking share from scar treatment heavyweights.